

はじめに
今日はファイルやインターネットについて理解を深め、インターネットから情報を効率よく得る方法について学びましょう。また、得た情報が正しいかをどう検証するかも考えてみましょう。具体的には、以下のことができるようになるといいです。
- ファイルとは何かを理解する。
- インターネットの仕組みを理解する。
- 閲覧しているウェブページのURI(URL)をコピペできる。
- 論文や本を探すのに大学図書館やCiNii(さいにぃ)のサイトを利用できる。
- 情報の信頼性について考え検証できる。
ということで、本日の内容は以下の通りです。
情報量の単位(デジタルデータの単位)
二進数、十六進数
コンピュータで扱う情報(データ)は、画像でも音楽でも動画でもテキストでも、すべて 0と1の組み合わせで構成されています。また、コンピュータの内部では、2進法で演算することでデータを処理します。(ハードウェアの一つに、CPUと呼ばれる中央演算処理装置があってそこで処理します。)
つまり、単純化してしまえば、コンピュータというのは、01001000‥という感じのデータを入力として受け取って、演算を実行し、11000101‥というようなデータを出力する装置です。
ただし、コンピュータ自身は入力データを数字だとか数値だとかで認識して処理できるわけではなく、電源のON(電気が通っている)とOFF(電気が通っていない)として認識して処理しています。それを、私たち人間は便宜上1と0として表現しています。
| 10進数 | 2進数 | 16進数 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | A |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
| 16 | 10000 | 10 |
| 17 | 10001 | 11 |
| ... | ... | ... |
十六進表記は、皆さんの場合は例えば「色」を指定する必要がある場合などに使用します。情報処理Ibでウェブページを作成しますが、ウェブページで使用する色は名前で指定する他、十六進表記でも指定できます。
ビットとバイト
前述の通り、コンピュータで扱うデータは0と1の組み合わせで表現されるわけですが、この0か1かを表す1桁分の最小単位をbit(ビット)といいます。1bitで、0か1かの2パターンの情報(データ)を表現できるわけです。2bitなら、2×2=4、つまり、00、01、10、11の4通りの情報を表現できます。
8bitなら、8桁なので、2の8乗、つまり256通りの情報を表現できます。
こんな感じに文字でも画像でも、すべてbitの塊で表現されているのですが、実際にコンピュータが処理するときには1ビット単位ではなく、いくつかのビットをまとめたものを1単位として処理することになります。この最小単位が1byte(バイト)で、これは8ビットに相当します。つまり、8桁の2進数を1単位にするのがバイトです。1バイトは00~FFの16進数2桁で表すのが一般的ですが、10進数なら、0〜255までの数値になります。
この先は、1000倍ごとに以下のような接頭辞をつけます。
- 1000Byte = 1 KB(キロバイト)
- 1000KB = 1 MB(メガバイト)
- 1000MB = 1 GB(ギガバイト)
- 1000GB = 1 TB(テラバイト)
これらの単位は、記憶装置における記憶領域のサイズや、データのサイズなどを表すために使われています。
Tera(テラ)の先も続いて、次はPeta(ペタ)ですが、現在よく見かけるのはTeraまでです。
ファイル(file)
ファイルとは
ハードディスクなどの記憶装置には、様々な情報(データ)が保存されています。この情報は、前述の通り0と1の組み合わせで構成されていますが、すべてファイル(file)と呼ばれるまとまりで保存されています。 つまり、アプリケーションプログラムも写真も音声もメールも意味のあるデータのまとまりはすべてファイルとして保存して使います。ファイル名
ファイルには名前を付けます。これをファイル名と呼びます。
ユーザがアプリケーションソフト等を使って作成したデータは、「ファイル名」を決めて「保存」することで「ファイル」になります。 そして、ファイルとして保存したデータを利用したい場合には、ファイル名を指定してデータを取り出します。 また、ファイルからデータを取り出すことを、「ファイルを開く」という言い方をします。一般に、ファイルに保存されたデータがアプリケーションの場合、「ファイルを開く」というのは、そのアプリを起動することであり、ファイルに保存されたデータが写真の場合、「ファイルを開く」というのは、その写真をユーザに表示して見せることです。- ファイル名の例
- memo.txt
- .signature
- mikatype.exe
- work.docx
- picture.jpg
- .signature
ファイル名の制約
ファイル名として使えない文字があります。どの文字が使えないかはファイルシステムによって違います。全角文字をファイル名として使えるシステムもありますし、使えないシステムもあります。使用を許可されない文字を使ってファイルに名前をつけようとしても、できません。 半角のアスタリスク「*」は、大抵の場合、使用できないので覚えておく必要があります。ファイル名の長さにも制限がありますが、皆さんが普通に使っている範囲では制限を超えるようなファイル名にはならないでしょう。つまり長さの制限は、気にしなくて大丈夫です。
ファイルの拡張子
ファイル名には、その種類を示す拡張子がつけられていることが多いです。(拡張子がないファイルもあります。) 拡張子は、ファイル名の一番最後の「.」(半角ピリオド)に続く3〜4文字の文字列です。コンピュータの扱うデータはすでに述べたようにbitの塊ですからファイルの中身は種類によらず0か1の数値の列です。ですから中身を直接見ても何のデータか判別できないので、拡張子によって種類がわかるようにしています。つまり拡張子はファイルの種類を表すので、例えば、.pdfという拡張子がついた名前のファイルをpdf(ピーディーエフ)ファイル、.jpgという拡張子がついた名前のファイルをjpg(ジェイペグ)ファイルというように呼ぶことがあります。
WindowsやMacなどのOS、またユーザも、基本的には、ファイル名の拡張子を見て種類を識別して、そのファイルを操作するアプリを決めます。 ただし、拡張子はあくまで名前で自由につけられるので、実際には、pdfファイルであっても、.pdfでなく.jpgという拡張子をつけてしまうことも可能です。ただこうすると、そのファイルの中身が本当は何だったのか、元の拡張子を知っている人以外にはわからなくなってデータが取り出せなくなることはよくあります。したがって、自分でファイルの拡張子も含めてファイル名を決める場合には、中身に応じて拡張子を選ぶようにしないといけません。
【参考】拡張子の例(眺めるだけで覚える必要はありません。)| 種類 | 拡張子 |
|---|---|
| 音声ファイル | .wav .mp3 .cda .wma .ogg |
| 画像ファイル | .bmp .gif .jpg .png |
| 動画ファイル | .wmv .avi .mpg .ogm .mov |
| テキストファイル、ハイパーテキストファイル | .txt .pdf .csv .html .css .xml |
| Wordファイル | .doc .docx .docm |
| Excelファイル | .xls .xlsm .xlsx |
| プログラムファイル、実行ファイル | .exe .com .bat .dll |
| 圧縮ファイル | .zip .lzh |
インターネットの基礎知識
コンピュータネットワーク(Computer Network)
コンピュータネットワークとは、複数のコンピュータ端末と周辺機器などを相互に接続して、接続されている端末同士で通信をして、データをやり取りしたり、共有したり(ファイル転送、共有)、片方の端末から片方の端末への命令を発して遠隔操作したり、といったことを可能にしたものです。単にネットワークと呼ぶこともあります。たとえ2台しかコンピュータがなくても上記の要件を満たせば1つのネットワークである、と言えます。LAN (Local Area Network)
限定されたエリアにおけるネットワークのこと。つまり物理的に近くにあるコンピュータ端末同士をつないだ(比較的小規模の)ネットワーク。家庭、企業、学校等で構築するネットワークで、イメージとしては同一敷地内のネットワークです。一番身近なのは、やはり家庭内LANでしょう。端末をLANケーブルで繋いで構築したLANが有線LAN、無線の親機にワイヤレスで子機として繋いで構築したLANが無線LAN。無線接続と有線接続を混在させてLANを構築することも可能です。
LANには、ネットワーク管理者と呼ばれる管理者が存在します。管理者がLANを構築し、利用ルールを決めたり、不正アクセス等の監視をします。 LANは誰もが自由に利用できるわけではなく利用者が限定されます。家庭内LANに見知らぬ他人のパソコンが接続していたら普通は困りますよね。
WAN (Wide Area Network)
LANより広い範囲のネットワーク。専用線などの通信回線を使って、物理的に遠くにある複数のコンピュータネットワークを相互に接続したネットワーク。例えば、小平キャンパスと千駄ヶ谷キャンパスのコンピュータ間をつなぐネットワーク、とか。同じ津田塾大学のネットワークですが、敷地が離れていますね。小平キャンパスで一つのネットワーク、千駄ヶ谷キャンパスで一つのネットワークを構築していて、その双方を繋いで、2つで1つの津田塾大学のネットワークを構築して、外部からは自由に接続できない、そういうイメージがWANです。インターネット
インターネットは、世界中の無数のネットワーク同士を相互に接続した、世界最大の巨大なネットワークの集合体であり、データが流れるための「道」の役割を担っています。LAN同士を繋いでWANになって、さらにこちらのWANとあちらのWANとそちらのWANをつないで‥というように、どんどん相互に接続していくイメージです。
「接続する」いうのは最初に述べたように「コンピュータがネットワークを介してデータをやりとりする」ことを意味します。自分の意図を相手に理解してもらい相手の意図を自分が理解できなければデータをやりとりできません。そのために通信に関する「取り決め」が必要になります。この取り決めを「通信規約(プロトコル)」と呼びます。
また、インターネットという「道」は、物理的には「光ファイバー」でできています。日本と海外との間には、海底ケーブルが何本も敷かれ、そこをデータが通っています。
データの通る道を整備しているのが、「回線事業者」です。日本の場合、NTT東、NTT西、KDDI、その他に電力会社やケーブルテレビ会社などが回線を提供しています。
インターネットは「インターネットサービスプロバイダ(ISP)」と呼ばれる「接続代行業者」と契約することにより、誰でも利用できます。ISPは単にプロバイダと呼ばれています。プロバイダは、回線業者が提供してくれる回線(一般的には光ファイバー)を使ってユーザがインターネットに接続できるようにしてくれます。日本では、OCN、So-net、@niftyなどを始め、非常に多くのプロバイダを選ぶことができるようになっています。
このように、インターネットに接続されたコンピューターは、「回線」を使って「プロトコル」に従うことでデータをやりとりできます。具体的には、ファイルの転送や共有、コンピュータ端末の遠隔操作などを遥か遠く離れた地にある別のWANに繋がれている端末間でも行えるようになります。もちろんどのコンピューターでも遠隔操作できたら困りますので、勝手に侵入できないように設定するのが普通です。
WWWもサーバクライアントシステムによって実現されています。
インターネットに接続する機器すべてに重複しないIPアドレス(これをグローバルIPアドレスと呼びます)を割り当てる必要があります。同じIPアドレスの機器が2つあったら、通信でデータを送信すべき相手が2つのうちのどちらの機器かわからなくなります。IPv4では、8bit×4の数値、つまり256の4乗=約40億個のアドレスが表現できますが、現在は全ての機器に割り当てるには足りなくなっています。IPv4に替わる新しいIP規格としてIPv6が決められています。IPv6でのIPアドレスはIPv4の4倍の128bitになります。IPv6でのアドレス表記は、128bitを16bitずつ区切り、16bitを16進数で表記します。区切りの記号は、IPv4では、「.」ピリオドでしたが、IPv6では「:」コロンになります。
ただ現在のところIPv4とIPv6の互換性がないために、スムーズに移行が進んでいません。
そこで今はIPアドレスを節約しながら使っている状態です。その節約に寄与しているのが、ローカルIPアドレス(プライベートIPアドレス)です。以下のIPアドレスは、ローカルIPアドレスとして使うことが決まっていて、個人が家庭内や組織内で自由に利用できます。
また、ローカルIPアドレスはインターネット上の一つの端末を特定することができないアドレスなので、内部からは(図ではスマホやパソコンやiPadからは)インターネットにアクセスできるけれど、外部の悪意あるユーザからのハッキング等のアクセスは避けられるという利点も生じます。
自分が使用しているグローバルIPアドレスは、https://www.cman.jp/network/support/go_access.cgi(外部ページ、クリックで別タブで開きます)などで確認できます。
ドメイン名は、企業、団体、教育機関、個人などに割り当てられる固有のもので、重複しないように管理され割り当てられます。例えば、tsuda.ac.jpというドメイン名は津田塾大学だけが使うことができます。
ドメイン名は半角文字で大文字小文字を区別しません。
ドメイン名の最後の方をみるとどんな組織かわかることもあって、例えば最後が「.gov」ならアメリカの政府関係、「.edu」ならアメリカの大学です。また「.jp」は日本、「.ca」はカナダ、「.uk」はイギリスといった意味を持っています。また最後が「.jp」の場合は、「.ac.jp」は大学などの教育機関、「.go.jp」は政府機関、「ed.jp」は小学校中学校高校などの18歳未満を対象とした教育機関、「.co.jp」は一般企業、「.ne.jp」はネットワークサービス会社です。
Web上にある資源(*1)を指し示すために、最初にURLという識別子(*2)が規定(*3)されました。その後、URNという識別子が規定されました。URLにしろURIにしろ「スキーム」と呼ばれる文字列が先頭にきます。スキームには、https:の他、ftp:、file:、mailto:など様々なものがあって、国際標準のものもそうでないものもあり、よく使用するものしか私も知りませんが、今後も確実に今後も増え続けることでしょう。そうなると、URLとかURNとかの区別がきっちりできるとは限らないし、URLでもURNでもないというのがでてくるかもしれません。とりあえずどうなってもいいように(という言い方も変ですが)、URLやURNを含む包括的な概念としてURIという識別子を規定した、という歴史的な流れがあります。
ブラウザに目的のウェブページのURLを入力することで、そのページが閲覧できます。
http://で始まるURLは、このHTTPプロトコルで通信するという意味です。
もう一つHTTPSというプロトコルがあります。これは、HTTPを拡張したHTTP over TLSというプロトコルです。HTTPSプロトコルでは認証局が発行するデジタル証明書(サーバ証明書)によってサーバの身元が保証され、データのやりとりはSSL/TLSで暗号化されます。認証局は複数存在します。またSSL/TLSというのは暗号化の方式の一つです。HTTPSプロトコルを使用するウェブページのURLはhttps://で始まります。
ブラウザ上でクレジットカード番号を入力してもらったり、IDやパスワードなどを入力してもらったりする際の秘密漏洩対策、また他のフィッシングサイトなどの偽サーバのなりすましでないことを保証するために、最近ではHTTPSプロトコルを利用するサイトが主流になりました。
この講義資料のウェブページを閲覧するためのURLは次のような形をしています。
https://edu.tsuda.ac.jp/~sirakura/2023t1/lec2.html
これは次のように構成されています。
ファイルの「パス名」については、別の回で説明します。index.htmlなどのいくつか特殊なファイル名は省略されることがあります。「https://www.tsuda.ac.jp/」などがそうです。また一般に.htmlという拡張子のファイルをHTMLファイルと呼びます。
URIスキームには、httpやhttps以外にも、ファイル送受信に関するプロトコル名のftpや、ブラウザが動いている端末上のファイルにアクセスするためのfile、メールの送信先を指定するmailtoなどがあります。
検索サービスは、Yahoo!のディレクトリと呼ばれるリンク集を人手で作成したところから始まりました。その後、ウェブページの数が増えるに従って、クローラと呼ばれるロボット(自動でデータを収集するソフト)が世界中のウェブページにアクセスして情報を集め、検索可能にする検索エンジン(search engine)が現れました。その代表がGoogleですが、現在は、Yahoo!もクローラを使って情報を集めています。そして、Microsoft BingがOpenAIのGPTと呼ばれるLLM(大規模言語モデル)を組み込んで、検索+AIでチャット形式で検索できるようにするという取り組みを始めたのが今年です。
パソコンやスマホの操作手順などがわからなくても、検索すれば大抵見つけることができます。例えば、ブラウザのブックマーク機能に関する手順を知りたいときには、「Chrome ブックマーク」のように2つのキーワードを半角スペース(半角空白)で区切って検索することで見つけることができます。
さらに、Microsoft Bingのチャットは「会話のスタイル」を「正確に(厳密に)」に設定して例えば「Chromeのブックマークの操作方法を教えて」と文章で入力すると、手順を教えてくれて、さらに、その手順が示されているウェブページを提示してくれます。
様々なデータがネット上で公開されています。 それらの中には、誰でも無償で利用・再配布・加工できるような形式で入手できるデータもあり、「オープンデータ」と呼ばれています。オープンデータの中には、国や自治体が収集・集計して公開しているものもあります。
データのファイル形式はCSV,Excel,PDFなどです。統計データがCSV形式で公開されている場合には、データをダウンロードして、ExcelやGoogleスプレッドシートなどのソフトで開けば、データの分析やグラフの作成ができます。
例えば医療や健康に関する情報は学術的に正しい情報と間違った情報が混在しているので注意が必要です。本として出版されていても内容の正しさが保証されているわけではありません。
情報の信頼性を見極めるためには以下のポイントを考慮してください。
では、上記のサイトの情報が信頼できるか考えてみます。
さて、論文の信頼性についてもう少し考えてみます。国際的に信頼されている学術雑誌に掲載されている論文なら信頼できますが、そうでないのはどうでしょう?個人で専門外の論文の内容を一次資料として確認しきちんと把握するのは難しいものです。簡単な問題でなく新型コロナのように複雑で研究論文も数多くあるとなおさらです。このときには、そのような論文を参考資料として挙げて解説してくれている専門家の意見が参考になります。ただし、専門家の意見も、「1人の専門家」の意見であれば信頼性が低いです。「多くの専門家が合意する意見」であれば信頼性が高いです。このため、学会や、上述の厚生労働省やCDCなどの公的機関の発信している情報で複数の公的機関で同じような情報が発信されていれば信頼性が高いといえます。
また論争があって、もし特定の学会の情報を疑う場合には、参考になるのは他国の学会の意見です。例えば日本の感染症学会の情報を疑うなら、他国の感染症学会の情報が根拠として必要になります。
それから、ウィキペディア(wikipedia)はよく間違いがあります。誰でも編集できるので信頼できるとは言えません。ウィキペディアで調べたことは、他のサイト(最終的には一次資料)で確認する必要があります。また、有名サイトのページでもレビューのように誰でも書き込んで編集できるサイトの情報は、個人の見解という受け止め方をする必要があります。
再提出は、Google Classroomの「授業」→「第2回 提出課題」→「課題を表示」→「提出を取り消し」→確認されたらさらに「提出を取り消し」→「第2回 提出課題」のGoogleフォームをクリック→「既に回答済みです」という文言の下の方にある「回答を編集」をクリック。そして、回答後に「送信」をクリックすれば再提出できます。
期限後に返却しますが、満点でなくても、再提出した方がよいと言われなければ再提出する必要はありません。
WWW (World Wide Web)とサーバクライアントシステム
WWW
「WWW」は、インターネット上に点在する様々な情報を発信したり受け取ったりするための「仕組み」のことです。
以下のような特徴があります。
Web(ウェブ)は蜘蛛の巣という意味があります。つまりWWWは「世界規模の蜘蛛の巣」という意味で、リンクによって世界中の情報がつながっていることを表現しています。もともとは、欧州原子核研究機構(CERN)で論文閲覧システムとして開発されたものが元になっています。
サーバクライアントシステム
情報システムは、サーバ・クライアント型と呼ばれるシステムで構成されることがよくあります。
このシステムにおいて、サーバとクライアントは、コンピュータネットワークを利用して情報を交換します。サーバは、サービスを提供するアプリケーションプログラムですが、サーバプログラムが動いているコンピュータ端末をサーバと呼ぶこともあります。クライアントは、サーバに対してサービスを要求するソフトです。通常、サーバはクライアントからの要求を待っていて、クライアントから要求があったときに、適切な応答を返します。
WWWサーバ
(ウェブサーバ)
情報を発信(提供)するためのアプリケーションプログラム。あるいはそのプログラムが動いているコンピュータ端末。インターネット上に無数に存在している。クライアントの要求に応じて、適切なサービスをクライアント側に提供する。例えば、自分が保存しているデータの公開など。
WWWクライアント
(ウェブブラウザ、単にブラウザとも)
サーバに接続して、情報を受け取る(取り出す)ためのアプリケーションプログラム。ブラウザの最も基本的な機能は、ウェブサーバから送られてくる情報を、人が見てわかるページ(ウェブページ)として表示することである。
Google Chrome,Safari,Microsoft Edge,Internet Explorer,Firefoxなどが最近はよく利用されています。
IPアドレス
インターネットは、コンピューター端末の相互接続のためにIP(アイピー、インターネットプロトコル)というプロトコルを利用しています。TCP/IP(TCPから分かれてできたのがIPなので)と呼ぶこともあります。
IPでは、ネットワークに接続している端末はIPアドレスという数値で識別します。
IPv4(アイピーヴィフォー、インターネットプロトコルバージョンフォー)のIPアドレスは、32桁の2進数です。表記する場合には、32bitを8bitずつに区切り、さらに10進数に変換して表記します。
例えば、133.99.161.13のように表記します。
これ以外のIPアドレスはグローバルIPアドレスと呼ばれます。グローバルIPアドレスは、インターネットの中で重複しないように管理されています。個人ユーザーは、プロバイダーと契約して、プロバイダーからIPアドレスを割り当ててもらいます。一般にIPアドレスだけでは個人の特定はできませんが、どのプロバイダーが割り当てたIPアドレスかはわかりますし、プロバイダーは、IPアドレスと利用された時刻などから利用者を特定することができます。従って訴訟などの際はプロバイダーに開示請求して個人を特定します。
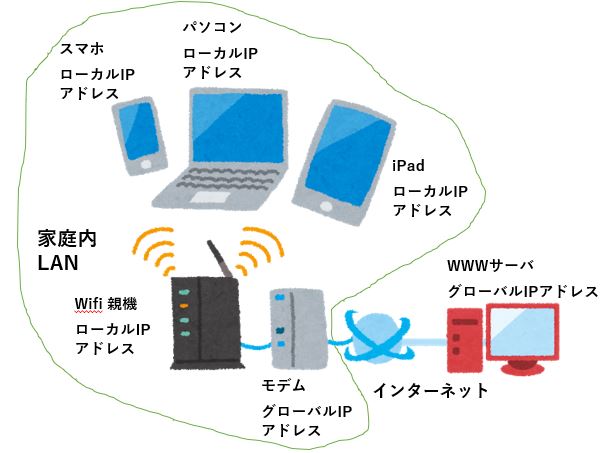 ローカルIPアドレスの使い方は次のような感じになります。家庭内LANを例にして図にしてみます。
プロバイダから支給されたモデムが家の中にあって、そこに無線LAN親機を繋いで、さらに無線で個人のスマホ、パソコン、iPadを繋いでいるのを図にしました。無線LAN親機とモデムは1台で済むようになっていることもありますね。
ローカルIPアドレスの使い方は次のような感じになります。家庭内LANを例にして図にしてみます。
プロバイダから支給されたモデムが家の中にあって、そこに無線LAN親機を繋いで、さらに無線で個人のスマホ、パソコン、iPadを繋いでいるのを図にしました。無線LAN親機とモデムは1台で済むようになっていることもありますね。
一般にローカルIPアドレスの使い方としては、LAN内の端末にローカルIPアドレスを割り当て、LANとインターネットの2つのネットワークの間に、プロキシサーバを置いたり、ブロードバンドルータと呼ばれる機器を置きます。
図の場合、モデムとあるのがブロードバンドルータの役割をしていて、スマホ、パソコン、iPad、そしてWifi親機にローカルIPアドレスを割り当てます。ローカルIPアドレスは重複せず家庭内LAN内での識別が可能なように、それぞれ別々のものを割り当てます。
そうして、LAN内の端末は、プロキシサーバやブロードバンドルータを介してインターネットにアクセスします。
具体的にはブロードバンドルータはインターネットに接続して、LAN内の端末、例えば図のパソコンの要求を聞いて、パソコンの代わりに情報を送受信して、受信した情報をパソコンに渡します。
ブロードバンドルータは、ローカルIPアドレスをグローバルIPアドレスに変換する機能を備えていて、ローカルIPアドレスを持つ端末がインターネットを通じて情報をやりとりする際に、ルータ自身のグローバルIPに置き換えて中継します。
こうするとグローバルIPアドレスは、プロキシサーバかブロードバンドルータだけに割り当てればよくなります。
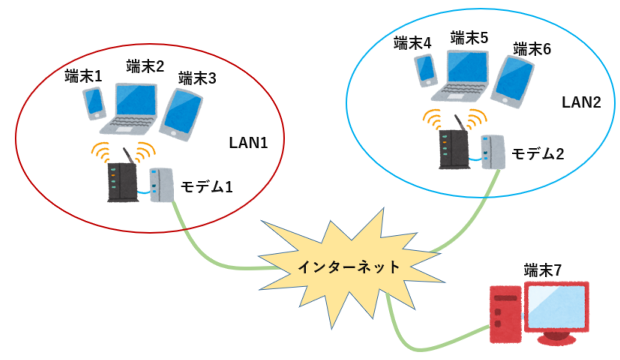 右図のようなネットワークがあって、LAN1とLAN2に接続されている端末1~6がローカルIPアドレスを割り当てられていて、モデム1とモデム2はグローバルIPアドレスが割り当てられているとします。このとき、以下の問題を考えてみてください。いままでの話が理解できていればわかります。
右図のようなネットワークがあって、LAN1とLAN2に接続されている端末1~6がローカルIPアドレスを割り当てられていて、モデム1とモデム2はグローバルIPアドレスが割り当てられているとします。このとき、以下の問題を考えてみてください。いままでの話が理解できていればわかります。
グローバルIPアドレスを確認する
例えばクレジットカードを使ってネット通販を利用していったりするときの認証(今カードがなくても、後々カードを持つようになって承認か否認か選ぶこともあるでしょう)でメッセージ内に自分の使用端末のIPアドレスが記述されていたりします。
ドメインとDNS
ドメイン
コンピューターはIPアドレスを使いますが、人間は一般にわかりやすく「www.tsuda.ac.jp」のような名前を使います。「www.tsuda.ac.jp」のような名前をホスト名、「tsuda.ac.jp」の部分をドメイン名といいます。
DNS
ホスト名とIPアドレスを対応させる仕組みがDNSです。
ホスト名とIPアドレスを対応させたデータベースは巨大になるので、ドメインに応じてデータベースを分散させて管理するようになっています。データベースを管理する「DNSサーバー」が世界中にあります。ブラウザに対し人間が「www.tsuda.ac.jp」のようにホスト名で通信相手のウェブサーバを指定したとしましょう。ブラウザは、まず基幹サーバにjpを担当するDNSサーバを教えてもらって、次にjp担当のDNSサーバからac.jpを担当するDNSサーバからtsuda.ac.jpを担当する津田塾大学のDNSサーバを教えてもらって、そこからwww.tsuda.ac.jpのIPアドレスを教えてもらいます。そして、ブラウザは、www.tsuda.ac.jpのIPアドレスを知って、津田塾大学のウェブサーバと通信できるようになります。
URI と URL
ブラウザで閲覧することのできるページをウェブページといいます。
このウェブページが保存されている場所を特定するための方法をURI(またはURL)といいます。
URIは、「Uniform Resource Identifier」の略で、URLは「Uniform Resource Locator」の略です。
URLはインターネット上の「場所」を示す表記方式ですが、URIは、すべての情報資源を識別するための表記方式で「場所」の他に「名前」を表すこともあります。このようにURIはURLを含むもので、ウェブページを指定するURIはURLでもあります。両者は同じです。
さて、それでURN(Uniform Resource Identifier)という識別子ですが、urn:スキームから始まる識別子として規定されています。例えば、先ほど出てきたIETFという団体が定めたRFC2396という文書を示すURNは、
urn:ietf:rfc:2396
と記述できます。ちなみにrfc2396にアクセスするためのURLは例えば、
https://tools.ietf.org/html/rfc2396
です。このURLに含まれる「html/rfc2396」はtools.ietf.orgというサーバ内に保存された情報のありかを示すパス名ですが、フォルダ名は変更するかもしれませんし、保存場所を別の場所に移動させればこのURLは将来変わるかもしれません。これに対し、urn:ietf:rfc:2396によって示される文書そのものは変わることがありません。つまり、URLで示す「位置」は変わるかもしれないので、将来にわたって変わらない「名前」で特定の資源を一意に識別しようとして考えられたのがURNというものです。(では、それをどう使うかというとまだあまり実用的ではないかな、という気がします。気がするだけですけど。)
他には、特定の本を示すURNもあって、これにはISBNコードを用います。
URN:ISBN:978-4-915512-37-7
(大文字小文字を区別しません)
URLを用いたウェブページの閲覧
URLにはファイル名とそのファイルを保持するウェブサーバのホスト名を含んでいます。それで、ブラウザは、URLで指定されたウェブサーバとこんな感じの通信をして、データをもらってウェブページを表示します。
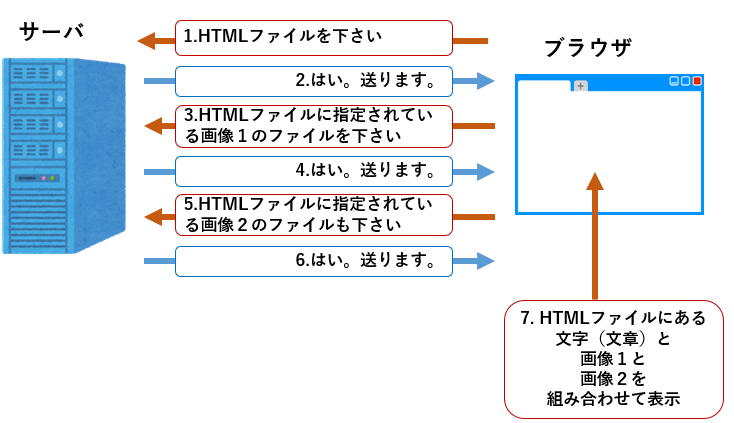
このデータ通信はHTTP(HyperText Transfer Protocol)というプロトコル(通信規約)に従って行われます。
https://edu.tsuda.ac.jp/~sirakura/2023t1/lec2.html
URIスキーム://サーバ名.ドメイン名/ファイル名(パス名)
ブラウザ
ブラウザにはSafari、MicrosoftEdgeなど複数のアプリがありますが、ここではGoogle Chromeを例に、ブラウザに関する基本的な操作を説明します。
起動方法いろいろ
南校舎の端末
 をクリック→
をクリック→ をクリックします。
をクリックします。
アプリケーション一覧から探して起動する。
 キー→ (Windows 11は、さらに右上の[すべてのアプリ >]をクリック→)一覧表示からGの項目にGoogle Chrome
キー→ (Windows 11は、さらに右上の[すべてのアプリ >]をクリック→)一覧表示からGの項目にGoogle Chrome  があると思うので、それをクリックします。
があると思うので、それをクリックします。
 【Mac】 DockにあるFinger
【Mac】 DockにあるFinger アイコンをクリック→ Finderウィンドウのサイドバーの「アプリケーション」をクリック→ 一覧からGoogle Chrome(右図参照)をダブルクリックします。
アイコンをクリック→ Finderウィンドウのサイドバーの「アプリケーション」をクリック→ 一覧からGoogle Chrome(右図参照)をダブルクリックします。
アプリケーション名(の一部)で検索して起動する。
WindowsにしろMacにしろ、起動したいアプリのアイコンが見つからないときは、以下のように検索して、結果として表示されたアプリ(アイコンと名称が一緒に表示される)をクリックしても起動できます。
 や検索ボックスをクリックして「chrome」と入力します。
や検索ボックスをクリックして「chrome」と入力します。
虫眼鏡アイコンや検索ボックスが表示されていない場合、Windows10なら、タスクバー上で右クリック→ [検索]→[検索ボックスを表示]で、表示できます。Windows11なら、タスクバー上で右クリック→ [タスクバーの設定]→[タスクバー項目]の[検索]をオンにすると表示できます。
 をクリックして、「chrome」と入力します。
をクリックして、「chrome」と入力します。
終了
基本操作
下図は大学のWS教室の端末でWindowsを選択してログインしたときに起動しているGoogle Chromeを例にしています。Mac版も似たような外見です。ただWindows版はブラウザの右端のメニューに「終了」があって、Mac版はないので、Mac版ではデスクトップ左上の「Chrome」メニューから「Chromeを終了する」を選んで終了します。
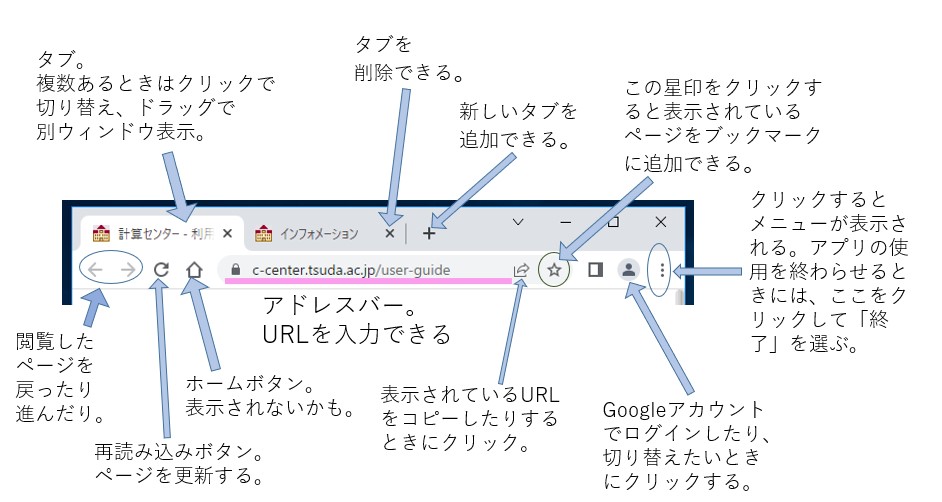
アドレスバー
ブラウザの上部にアドレスバーがあります。ここに見ているページのURI(URL)が表示されます。
(一見するとURIスキームの部分は隠されて表示されていなかったりします。)
またアドレスバー内をクリックしてから直接URI(URL)を入力してreturn(enter)キーを押すことで、そのページを表示させることもできます。
Chrome以外のブラウザ
 (Windows)/
(Windows)/ (Mac)アイコンをクリック
(Mac)アイコンをクリック
[Ctrl]/[Command]キーを押しながら[a]キー
[Ctrl]/[Command]キーを押しながら[c]キー、あるいは右クリックして「コピー」を選ぶ
コピペしたURLに先頭にURIスキームがあることを確認しましょう。アドレスバーにURIスキームが表示されていない場合でもコピペしたときに表示されるはずです。表示されてないとURLとして不完全です。アドレスバーに全角文字が表示されていても、サーバとクライアントとの実際のやりとりでは半角英数字や記号に変換して処理されるため、コピペすると「%」を含む英数字になります。例えば「天」という文字は、「%E5%A4%A9%0D%0A」と変換されて表示されます。
ページ内を進む/戻る
どういうやり方でも構いません。さすがにできない人はいないと思います。
例えば、ページ内をクリックしてから、タッチパッドでスクロールすればページ内を進んだり戻ったりできますね。
ページの再読み込み
ニュースサイトなどは、表示してから時間が経つと内容が更新されていたりします。最新の内容にしたい場合に、再読み込みボタン をクリックします。大抵の場合、アドレスバーの右とか左にあると思います。
をクリックします。大抵の場合、アドレスバーの右とか左にあると思います。
リンク先へ飛ぶ
ウェブページの場合、クリックすると別のページ(あるいはページ内の別の場所)が表示される箇所(文字列とかアイコンとか)がありますよね。このような箇所は「リンクが張られている」という言い方をします。そして、クリックして別ページを表示させることを「リンク先に飛ぶ」という言い方をします。
前のページに戻る/次のページに進む
これも知っていると思います。矢印ボタン(矢印アイコン)が上部か下部の左端の方にあって、色が薄くなっているときはそれ以上戻ったり進んだりできませんが、色が濃くなっているときには、今まで閲覧した履歴にしたがって、ページを戻ったり進んだりすることができます。この矢印ボタンを右クリックすることで、それまでに閲覧したページの一覧が表示されて、それを選ぶことで、何ページも前に戻ったり、ずっと後へ進んだりできる場合も多いです。
タブ
Google ChromeもSafariもMicrosoftEdgeにも、タブという機能があって、複数のページを同時に見られるようになっているはずです。
一つのタブでこの講義資料を閲覧しながら、別のタブでGoogle Classroomを見る、ということができると何かと便利です。

こんな感じに「タブ」はページの上の方にあります。
ここをクリックすると前回の講義資料が別のタブで開くはずです。第1回の講義資料が表示されたタブと、第2回の講義資料のページが表示されたタブが切り替えられるか試してみて下さい。
ブックマーク(お気に入り)
「ブックマーク」とか「お気に入り」などの名称で、頻繁に見るページを登録しておく機能がついていると思います。登録したり、登録内容を整理できるようになっておくと便利です。
ブックマークに関する操作の説明は、外部ページのGoogle Chromeヘルプ ブックマークを作成、表示、編集する(クリックで別タブで開く) を参考にしてください。
情報検索
ウェブコンテンツを探す
GoogleやYahoo! Japan、Microsoft Bingなどのサイトで検索サービスを利用したことがあると思います。
演算子
検索サイトは複数ありますが、その多くのサイトで共通するようなものをいくつか挙げておきます。ただ検索サイトによっては使えない演算子やコマンドもあるかもしれません。また特定の検索サイト独自のものが他にもあったりします。
演算子 用例 意味と注意点
スペース A B C
A B Cのすべてを含むページを検索する。スペース区切りで、キーワードを列挙するとand検索となります。
OR A OR B
AまたはBを含むページを検索する。ORは大文字で入力し、前後に半角スペースを入力してください。AとBの両方が含まれるページも検索結果に含まれます。
( ) (A OR B) C
AまたはBを含み、かつCを含むページを検索する。半角の括弧記号で、一つのまとまりを指示します。AとBとCが含まれるページも検索結果に含まれます。
- A -B
Aを含むがBを含まないページを検索する。「―」はマイナス記号で、直前に半角スペースを入力する必要があります。
" "A"
Aをワンフレーズとして検索します。["」はダブルクォーテーション記号です。表記ゆれを無視したい場合や、文節、文章などをそのままのまとまりで検索したい場合にダブルクォーテーションで文字列を囲って検索します。通常は「送り仮名」と入力しても「送りがな」が含まれるページも検索結果として表示されたり、文章を入力してもそこに含まれる単語のand検索として検索結果が表示されたりします。
∗ "A∗B"
「∗」はアスタリスク記号で、任意の文字列に置換されます。AとBの間に任意の文字列が入るフレーズで検索します。例えば、"今日の∗はいい感じ"と入力して検索すると、今日の写真はいい感じ、今日の夜景はいい感じ、今日の仕事はいい感じといったフレーズを含むページが検索できます。
コマンド
検索範囲を特定ドメインに区切ったり、特定の拡張子を持つファイルのみを検索したりといったことがコマンドを使用することで可能になります。複数のコマンドを組み合わせたり、先ほどの演算子と組み合わせたりすることが可能です。
また、コマンドの前には半角スペースを入力します。
コマンド 用例 意味と注意点
site:
キーワード site:URL
指定したサイト内でキーワードを含むページを検索します。例えば、「粗大ごみ site:www.city.kodaira.tokyo.jp」とすると、小平市公式ホームページ内で粗大ごみという語を含むページを検索します。
質の高い情報を得るために、「site:ac.jp」(大学機関)や「site:go.jp」(政府機関)を付けて検索するのもよくあります。
filetype:
filetype:拡張子
拡張子を指定して検索します。「filetype:pdf 委任状」とすると委任状を含むpdfファイルを検索します。小平市役所に提出するpdf形式の委任状で印鑑登録に関するものを探したいときには例えば「委任状 印鑑登録 filetype:pdf site:www.city.kodaira.tokyo.jp」と検索することができます。
related:
related:URL
指定したURLと関連性の高いサイトを検索する
cache:
cache:URL
Google検索でのみ使えるコマンドかもしれません。閲覧したいサイトやページが削除されてしまって確認できないとき、一定期間のうちなら、Googleが保存しているデータが残っているので、そこから検索して探すことができます。
link:
link:URL
URLで指定したwebページにリンクしているページ、つまり被リンク先を検索します。
自分のブログなどに他の人がリンクを張っているかどうかを確認したいときなどに使用します。
本や論文を探す
以下は、文献検索、論文検索、記事検索などを行いたい場合に、よく使用すると思われるサイトです。
クリックでそのサイトに飛びます。
有用な学術情報(の一次情報)は、基本的には英語で発表されています。Google翻訳やDeepLなどの翻訳サービスも利用すると効率よく情報を探せるかもしれません。また、ChatPDFのような機能を使うとPDFファイルを読み込ませて、チャット形式で中身を要約してもらうこともできます。
書籍だけでなく、オンライン資料として、ジャーナル(電子版の学術雑誌や論文誌)、新聞記事、辞典や辞書など、大学が契約している有料で高品質な情報源にアクセスできます。
詳しくは、オンライン資料ガイドを見て下さい。
オンラインサービス一覧
論文や研究データを探すときにとても便利なサイトです。オンラインジャーナルのような学術情報は高額ですが、大学などに所属していなくても利用できるようにしようという動きがあって、大学の研究成果に自由にアクセスできるデータを探す
レポートなどで何かを主張するときには、個人的な主観やエピソードではなく、客観的な事実やデータに基づいてその主張の妥当性を示さなければいけないことがあるでしょう。
データカタログサイト。 日本のオープンデータを集約している公式ポータルサイトです。
気象庁の気象データなどの各省庁が公開しているデータや、地方公共団体などが公開しているデータを検索できるようになっています。
日本の統計が閲覧できる政府統計ポータルサイトです。各府省庁が公表する統計データを集約して、分野やキーワードで絞り込んだり検索したりできます。
地域経済分析システム。政府統計データが集約されているサイトで、都道府県や市町村の単位でデータを簡単に可視化できるようになっているのがe-Statと違います。一部民間企業が提供するデータも利用できます。
検索で気を付けること:情報の検証
情報には間違いがあるということを常に忘れないようにしないといけません。
ネットで得られる情報にしても、本で得られる情報にしても、信頼できるものもあれば信頼できないものもあります。情報を鵜呑みにせず、疑問をもって検証し評価することが重要です。
例をみてみましょう。例えば、新型コロナワクチンについては、様々な情報があります。それらについては、科学的に誤謬があるかないかを検証します。例えば、「新型コロナワクチンQ&A」(クリックで別タブで開きます)というサイトがあります。ページには「厚生労働省」とあります。次に内容を見てみましょう。このQ&Aの中の例えばこのページ(クリックで別タブで開きます)を見て下さい。そうするとページの下部に「参考資料」が緑の字で記述されていて、CDCの報告や論文へのリンクになっています。論文の掲載されている学術雑誌名は、「N Engl J Med」とか「Lancet」。「N Engl J Med」はNEJMと表記され、「Lancet」もランセットと表記されニュースサイトなどで目にしたことがあるのでは?国際的に信頼されている学術雑誌です。
以上の理由からこの情報の信頼性は高いと評価できます。
提出課題
期限
来週火曜日までです。
提出課題
以下の問いに答えて下さい。回答は、Google Classroomの「第2回 提出課題」とあるGoogleフォームに記述して下さい。回答を入力して送信することで課題提出となります。
 回答を送信した後、右図のように「課題が添付されていません」というメッセージが表示されても「提出済み」と表示されていれば問題ありません。
回答を送信した後、右図のように「課題が添付されていません」というメッセージが表示されても「提出済み」と表示されていれば問題ありません。



採点基準
再提出について
期限後の提出や再提出は減点対象になりますが、期限内であれば編集しなおして提出し直しても減点されません。
次回は